Presenting Oral Texts with Transcriptions Online
For several years I have been tracking the progression of how interlinear glossed texts (IGT) are interacted with online. This has several dimensions:
- the reason for the interaction and the goals of the interaction
- the visual layout and concepts driving the interaction
- the supporting technology choices used to make these interactions happen
- also the content of glosses used in the texts.
With regard to the first point above, I find that corpus tools generally fall into one of three broad catagories and this holds true even for browser based tools: Crafting, Display & Navigation, and Information Extraction & Pattern Discovery. Even though EXMARaLDA is not a browser based corpus too these catagories are exemplified in its documentation:
EXMARaLDA is a system for working with oral corpora on a computer. It consists of a transcription and annotation tool (Partitur-Editor), a tool for managing corpora (Corpus-Manager) and a query and analysis tool (EXAKT)
I have used this three way distinction to catagorize some of the different software options available for browser based interactions with IGT data1.
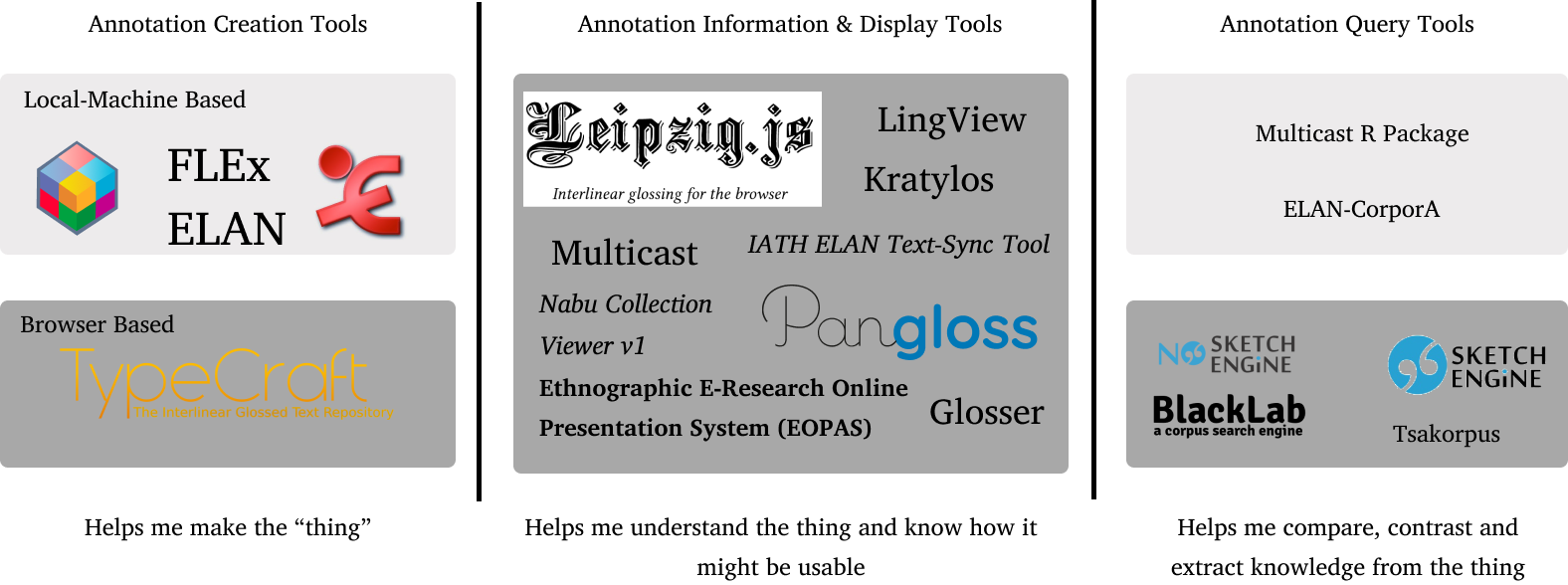
Types of browser based tools Credit: Hugh Paterson III
While what is presented in terms of the content is still very important, how it is presented in an interactive mode is also important. That is, how is the experience crafted around the audio or video and the transcribed segments in terms of the interaction design and visual design? I started to compile a list of these interactions which I present below. However, two significant components are influential in the life cycle of software and hence these interactions. First, the viral nature of the interaction, i.e., how easy is it to propagate the interaction in new contexts. Second, what is the life cycle of the technology undergirding the browser based experience? That is, how does the technology choice expose the user to obsolecence and technolgical debt. These two factors should be top ranking considerations when a project desires to “publish” or present interlinear texts online. In addition to these two factors, the following three design considerations will also impact the sustainability and maintainability of the online presence for the corpora and ought to be considered while planning for implementation.
- The first consideration is, is there a required separation between data (content) and presentation? By separating on these lines the code produced to present the interlinear text can be re-used liberally across texts and projects, and the visual presentation can be adjusted and applied to texts at scale.
- The second consideration is, what is the quantity of dependencies that a visual presentation requires? That is, are there server based requirements for the generation of the visual presentation, or can the presentation happen without the server? Server based presentations require a long term maintenance plan. More dependencies require that the software be updated as each dependency evolves (potentially motivated by security issues). Dependencies may drop features that current interactions deemed important.
- The third consideration is what is the purpose of the web-presentation? There are different classes of tools with respect to interlinear glossed texts. Arguably, the one of primary importance is the archived version. That is, where is the text archived and can the archived version’s annotation be viewed while the audio is heard at the same time. A secondary consideration then is the working copy, or what can one do with the interlinear glossed text and how easy is it for people other than the author of the interlinear glossed text to do comparative searching across the text or in conjunction with other texts. Then a third consideration, is how is the canonical reference of the archived version persisted through to the working copy. That is, if the interlinear glossed text it loaded into an online system for investigation, does that system create new identifiers for the searches conducted or does it respect existing identifiers?
With these issues in mind I have been collecting images of the visual presentation of interlinear glossed texts online. In addition to my purpose for looking at ongoing evolution of the technical presentation of interlinear glossed text, I have been looking for a system that meets the requirements of points number one and two for use on a portfolio website like mine. Stated another way, I am looking for a tool which takes ELAN or FLExTexts and matches them with audio or video in the browser, rather than on a server. I want the tool to be limited to HTML5, JavaScript, and CSS3+.
This is just a short list of tools for presenting time-aligned texts online. These would be in the middle category of the illustration above as they are designed for presentation and discovery of the resource rather than information extraction2.
Requires no Database
Leipzig.js
Produced by: Ben Chauvette German example showing output and code taken from the leipzig.js website
Credit: Ben Chauvette
Links: https://bdchauvette.net/leipzig.js ;
Github,
npm package.
Notes: This JavaScript library lines up interliear glosses based on spaces in the text file. Each row must be its own HTML paragraph. It can then number them for use as examples. It does not connect the the text to audio or video files, but it is great for use on blogs and websites.
Glosser is a similar kind of product, written in jQuery (JavaScript), but in my quick 3.5 minute review it looks like Leipzig.js has more features than Glosser.

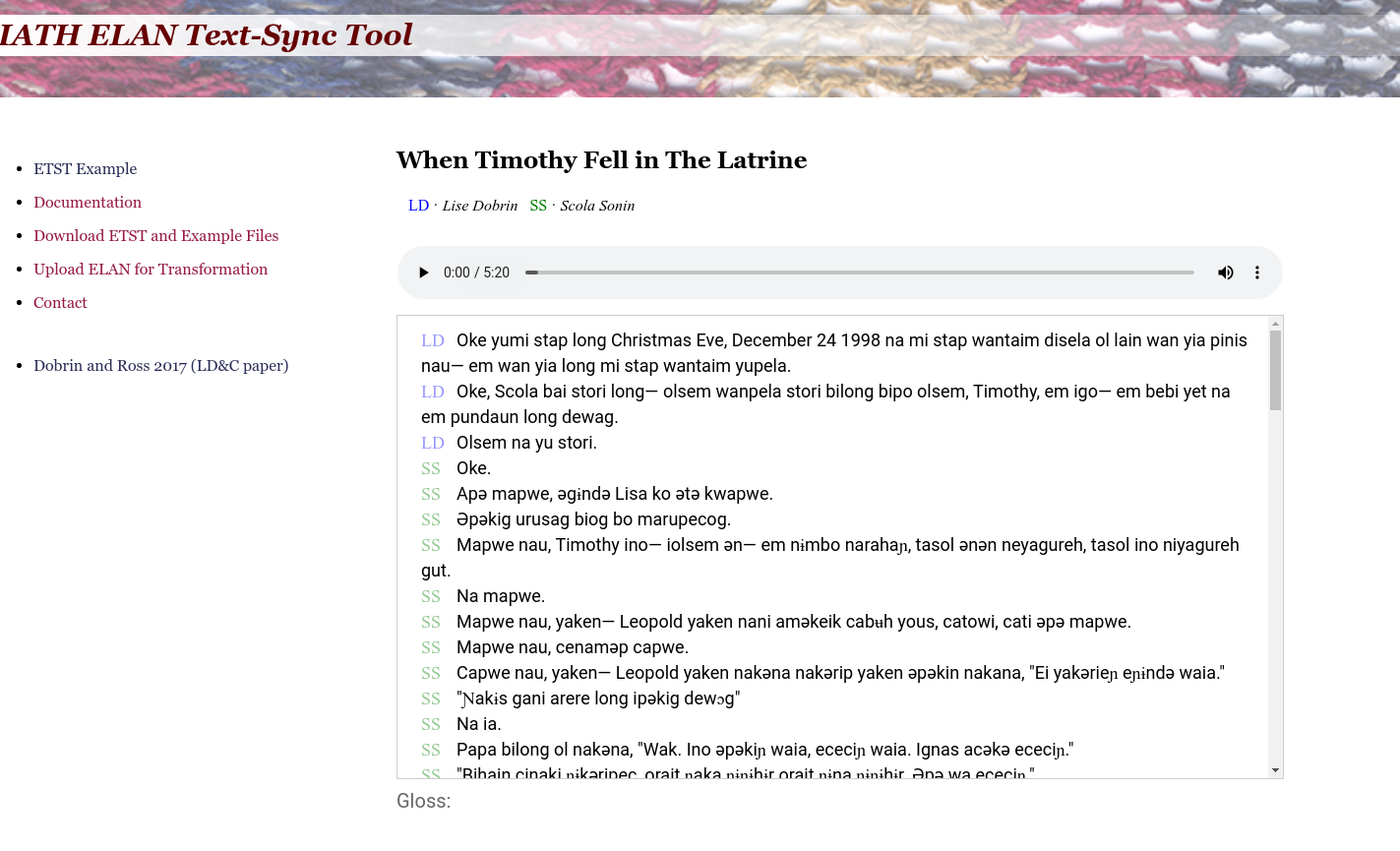
IATH ELAN Text-Sync Tool (ETST)
Produced by: Lise Dobrin & Douglas Ross
(Citation: Dobrin
et al.,
2017)
Dobrin,
L. & Ross,
D.
(2017).
The IATH ELAN Text-Sync Tool: A Simple System for Mobilizing ELAN Transcripts On- or Off-Line.
Language Documentation & Conservation, 11. 94–102. Retrieved from
http://hdl.handle.net/10125/24726
Time aligned audio and text where text is automatically highlighted as the audio plays.
Credit: Lise & Douglas
Links: http://community.village.virginia.edu/etst/
Notes: This script uses command-line PHP to convert ELAN texts to HTML and align them to audio or video files. This solution works completely within the browser and does not require a server once the annotation files are processed.
LingView
Produced by:
(Citation: Pride
et al.,
2020)
Pride,
K.,
Tomlin,
N. & AnderBois,
S.
(2020).
LingView: A Web Interface for Viewing FLEx and ELAN Files.
Language Documentation & Conservation, 14. 87–107. Retrieved from
http://hdl.handle.net/10125/24916
Links: https://github.com/BrownCLPS/LingView
Notes: Works with video, audio, ELAN files, FLExTexts, and does not require a server. Does depend on Node, which is a JavaScript framework.

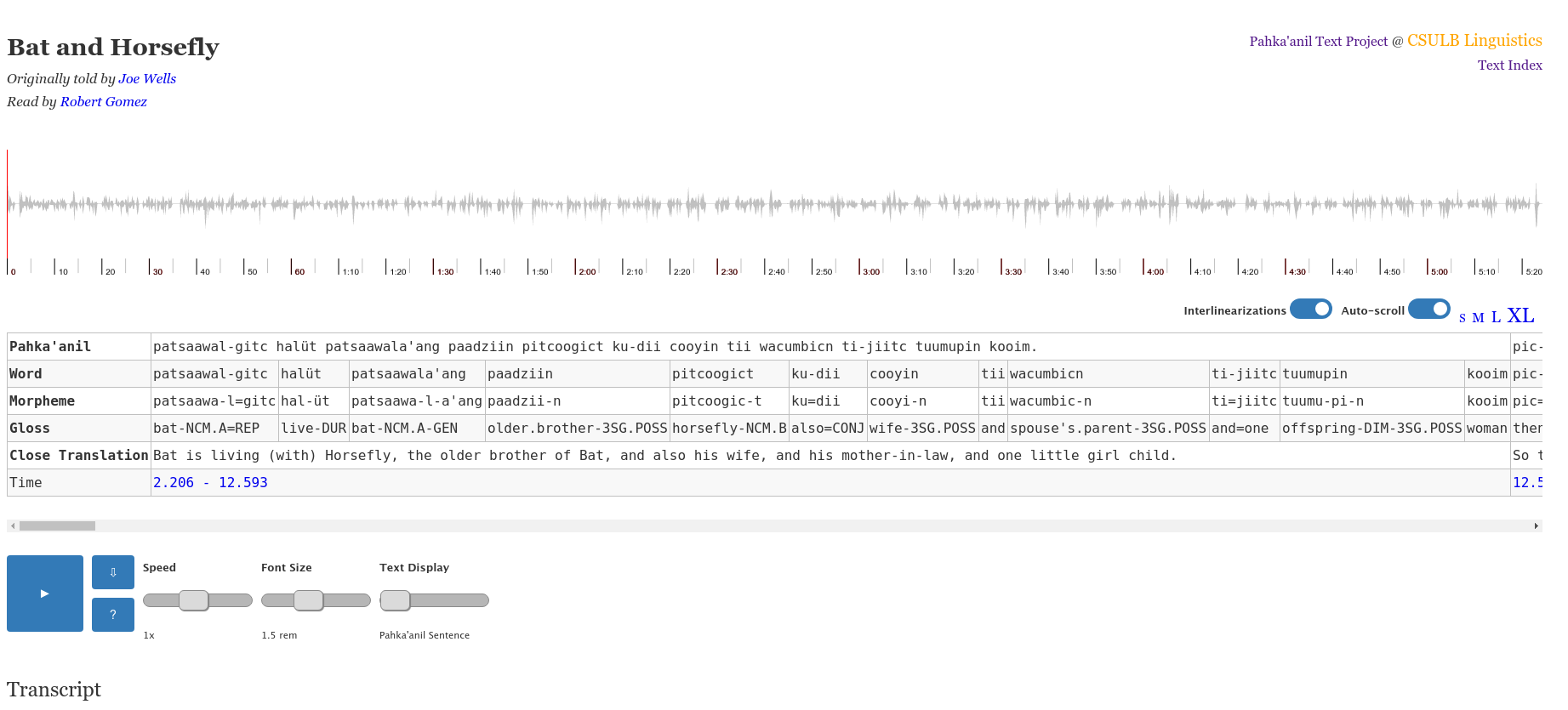
California State University Long Beach Interface
Produced by: Michael Ahland & Cem Demir as part of the Pahka’anil Text Project
Links: https://web.csulb.edu/projects/lingresearch/pahka'anil/text/bat-and-horsefly
Notes: This interaction does not appear to be downloadable as a re-usable/re-deployable package. However, the files are completly accessable for grabbing and subsequent modification. The setup currently uses
wavesurfer.js for media interaction and
.vtt files, which are type of sub-title file. In an alternative to using to the use of .vtt files is to use an
existing wavesurfer.js plugin built for use with ELAN files. One major difference between these presentations is the orientation of the table which presents the interlinear glossed texts.
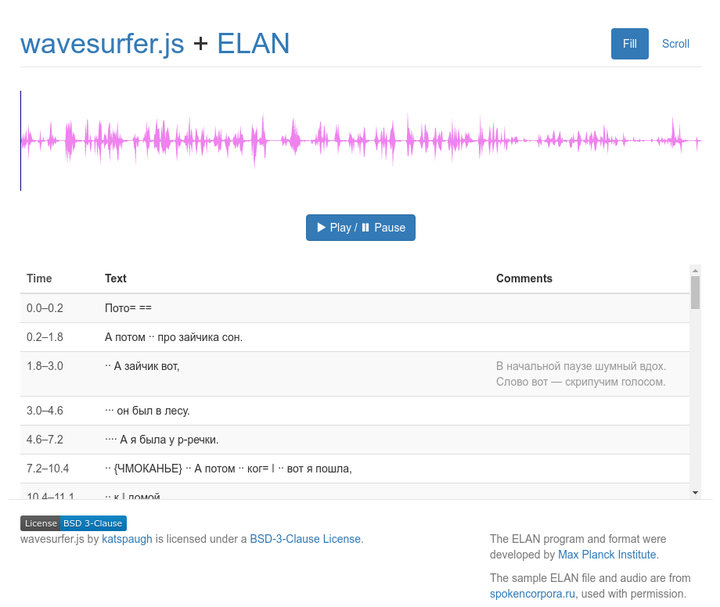
wavesurfer.js + ELAN
Produced by: J. Reuben Wetherbee
Links: https://wavesurfer-js.org/example/elan/index.html ; https://wavesurfer-js.org/example/elan-wave-segment/index.html
Notes: The ELAN plugin to wavesurfer.js was authored by
J. Reuben Wetherbee. It appears in the wavesurfer.js documentation examples, but not in the
main site’s list of plugins. Video.js is another project which can
display video and text tracts. There is also
a plugin which connects video.js to wavesurfer.js [
Github repo ]. So it seems that there might be a possibility to use one of either of these methods to present text annotations from ELAN and video together. However, I have not found any examples of this yet.
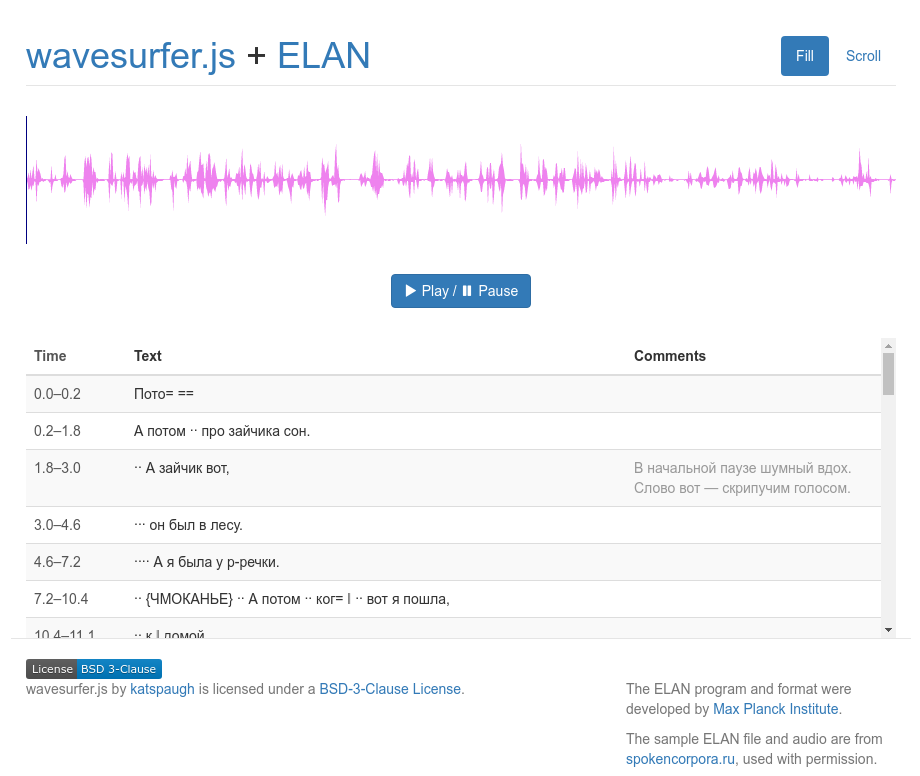
Require Back-end Databases
Ethnographic E-Research Online Presentation System (EOPAS)
Produced by: Nick Thieberger
(Citation: Schroeter
et al.,
2006)
Schroeter,
R. & Thieberger,
N.
(2006).
EOPAS, the EthnoER online representation of interlinear text. In Barwick,
L. & Thieberger,
N. (Eds.),
Sustainable Data from Digital Fieldwork. Proceedings of the conference held at the University of Sydney, 4-6 December 2006. (pp. 99–124).
Sydney University Press. Retrieved from
http://hdl.handle.net/2123/1297
&
(Citation: Thieberger,
2006)
Thieberger,
N.
(2006).
An ethnography of the EthnoER project.
Retrieved from
http://hdl.handle.net/2123/1532
Links: https://github.com/eopas/eopas
Note: This was one of the earliest online presentations which linked grammars with texts. However, the system does not support collaborative editing or the creation of texts. It was originally designed to work with Toolbox formatted data, with other IGT formats support added later. It is open source and available via Github. It provides direct links to specific segments of the artifacts for the purpose of citation and referencing.
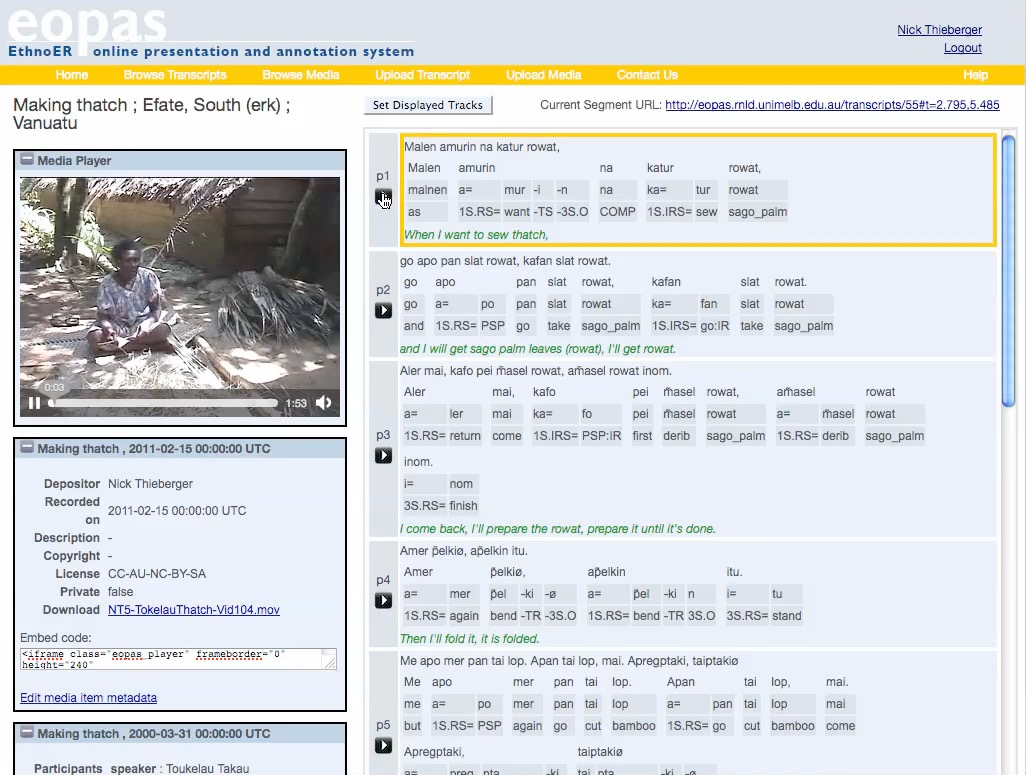
Screenshot of Eopas Credit: Nick Thieberger
Nabu collection viewer
Produced by: Nick Thieberger
Links: https://github.com/CoEDL/nabu-collection-viewer-v1
Note: In many ways this is a more modern evolution of Eopas. I can be seen when logged into
PARADISEC.
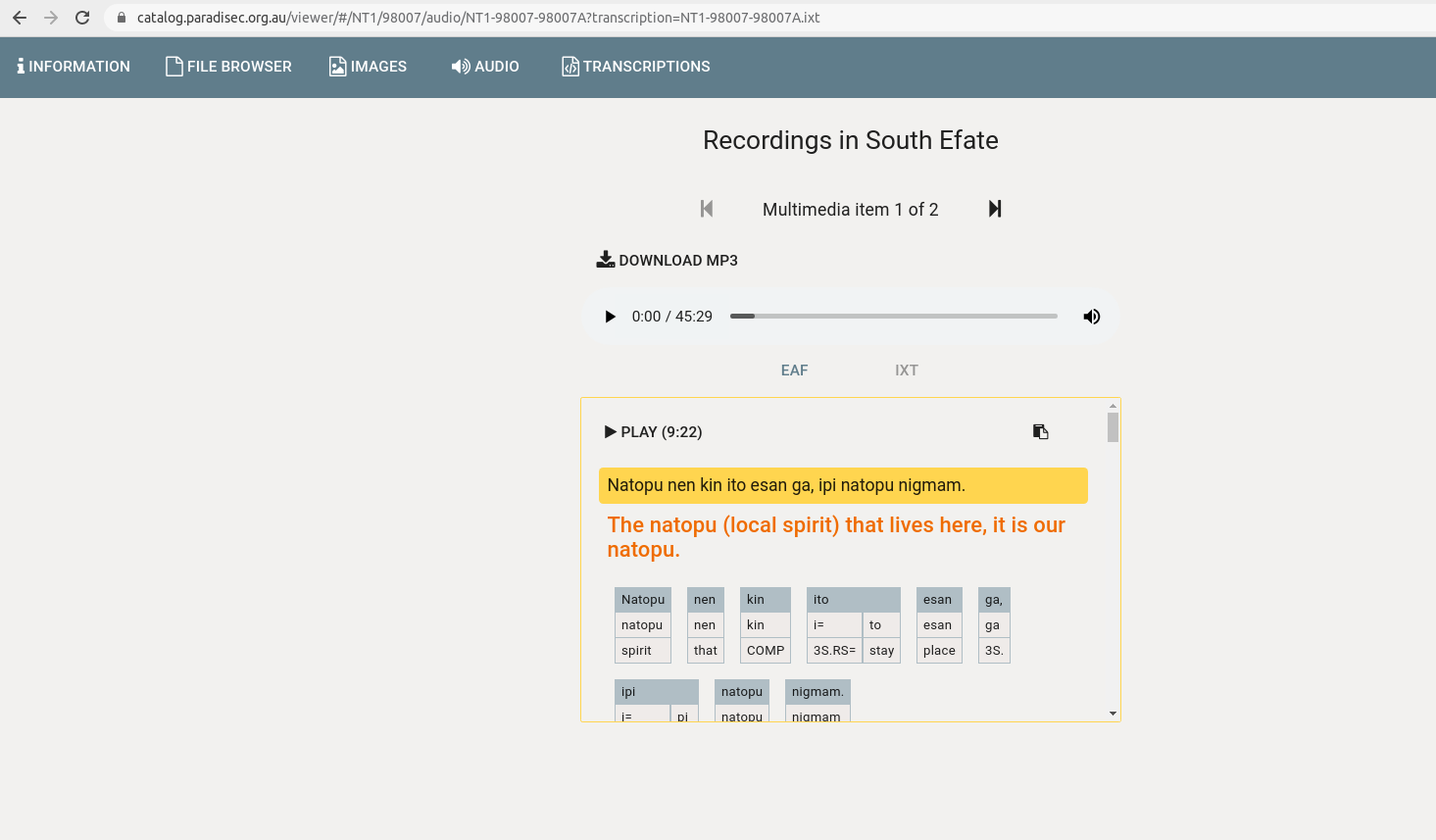
Screenshot of Nabu Collection viewer Credit: Nick Thieberger
TypeCraft
Produced by:
(Citation: Beermann
et al.,
2014)
Beermann,
D. & Mihaylov,
P.
(2014).
TypeCraft collaborative databasing and resource sharing for linguists.
Language Resources and Evaluation, 48(2). 203–225.
https://doi.org/10.1007/s10579-013-9257-9
Links: https://typecraft.org/tc2wiki/TypeCraft:About
Notes: This is software as service. It can not be locally deployed. This is a production system, that is it is designed to facilitate collaboration. It is based on MediaWiki. It is designed for collaborative creation of annotated texts. It does not align the texts for display with video or audio. The same purpose of this service could be accomplished if ELAN annotations were under version control (like git) and collaborators interacted with version control and used ELAN on their local computers.
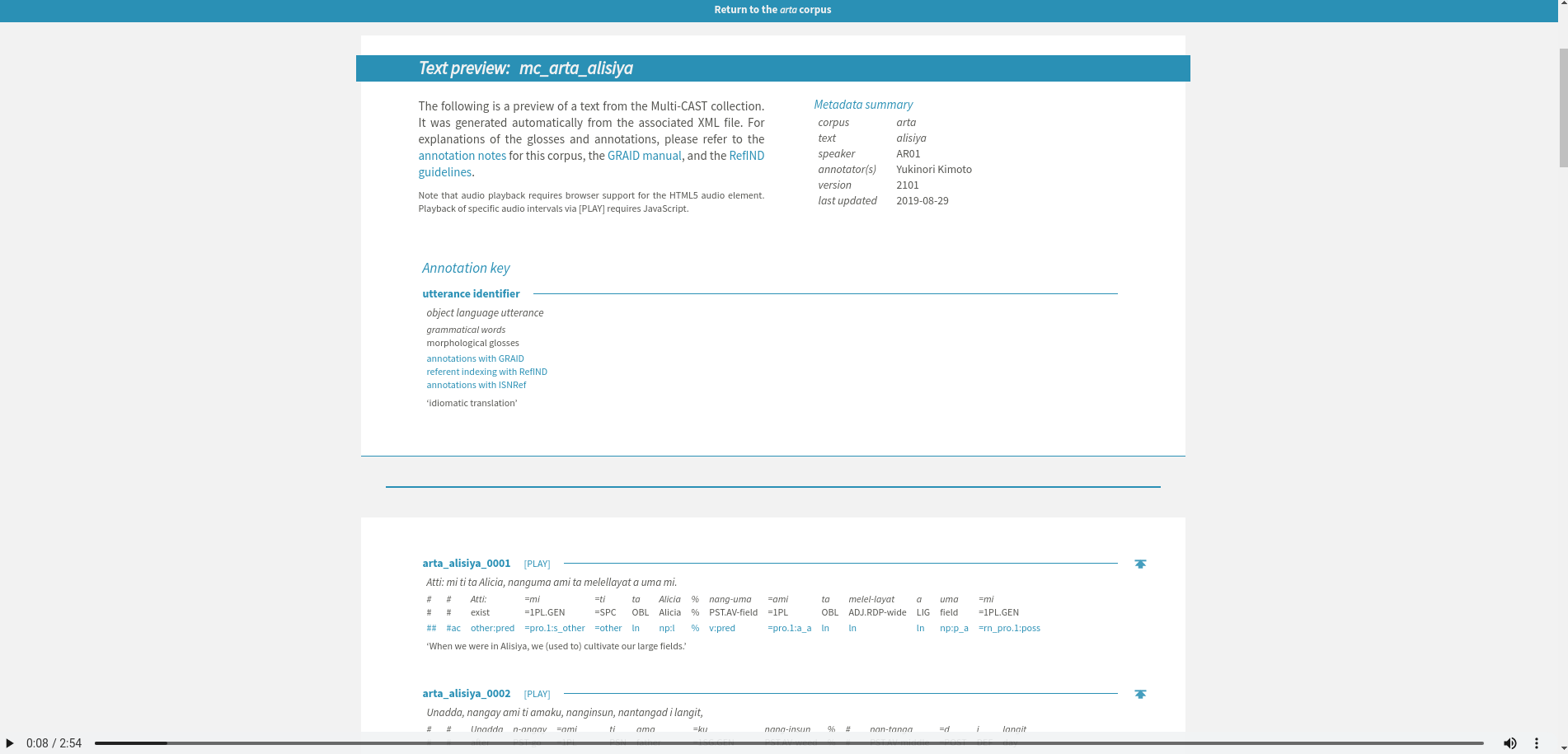
Multicast
Produced by: Geoffrey Haig & Nils Norman Schiborr
(Citation: Haig
et al.,
2016)
Haig,
G. & Schiborr,
N.
(2016).
Multi-CAST (Multilingual Corpus of Annotated Spoken Texts): Ein Projekt zur Erstellung und Auswertung mehrsprachiger Korpora für die Sprachtypologie.
Audio is at the very bottom of the screen. The text is not highlighted as it is played.
Credit: Geoffrey Haig & Nils Norman Schiborr
Links: https://multicast.aspra.uni-bamberg.de
Notes: The presentation software does not seem to be open source and accessible. However there is an
open source R package which one can use to download annotation files and programatically investigate them. The text being played in the audio is not highlighted, but one can quickly access the transcribed text and copy it out as formatted LaTeX for inclusion as interlinear text in an other document (a pretty nifty feature).
Pangloss
Produced by: CNRS-LACITO
(Citation: Thieberger
et al.,
2010)
Thieberger,
N. & Jacobson,
M.
(2010).
Sharing data in small and endangered languages: Cataloging and metadata, formats, and encodings. In Grenoble,
L. & Furbee,
N. (Eds.),
Language Documentation: Practice and values. (pp. 147–158).
John Benjamins Publishing Company.
https://doi.org/10.1075/z.158.15thi
(Citation: Michailovsky
et al.,
2011)
Michailovsky,
B.,
Michaud,
A. & Guillaume,
S.
(2011).
A simple architecture for the fine-grained documentation of endangered languages: The LACITO multimedia archive.
IEEE.
https://doi.org/10.1109/ICSDA.2011.6085973
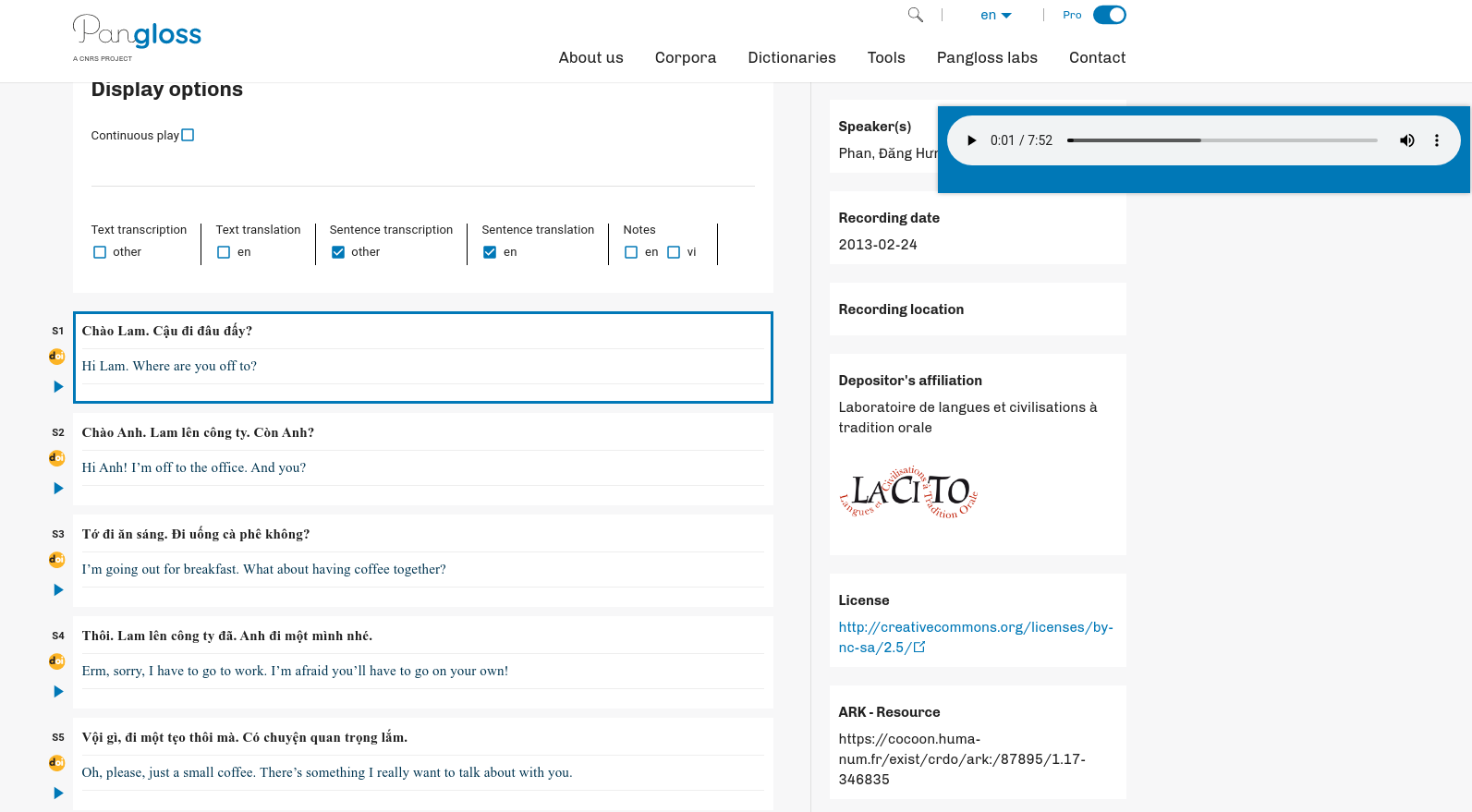
Links: [Example]: https://doi.org/10.24397/pangloss-0004676
Notes: As software the Pangloss interface is not downloadable. However, it is the front face of an archived collection. It is great for referencing a particular point in an audio or transcribed textual artifact, within an the archive’s canonical location for the item. The Pangloss use of DOIs to access the components of a resource is discussed in
(Citation: Vasile
et al.,
2020)
Vasile,
A.,
Guillaume,
S.,
Aouini,
M. & Michaud,
A.
(2020).
Le Digital Object Identifier, une impérieuse nécessité ?L’exemple de l’attribution de DOI à la Collection Pangloss, archive ouverte de langues en danger.
I2D - Information, données & documents, 2(2). 155–175.
https://doi.org/10.3917/i2d.202.0155
.
Eastlingplayer
Produced by: CNRS-LACITO & Alexis Michaud
Links: https://github.com/CNRS-LACITO/eastlingplayer
Notes: Eastling Player is part of the
Eastling suite: Easy Annotation and Synchronization Tool for linguists. It is developed in PHP and requires a server. It was developed in response to perceptions of server lag times in early versions of Pangloss (in the
presentation interface managed by Villejuif; there are two interfaces). These versions of Pangloss converted ELAN files (XML) to HTML on request. As these XML files got longer they affected server-client transmission times. Technicians opted to parse these XML files into a databases to decrease load times. This is an interesting use of tools because the XML transforms could have been maintained and the HTML outputs cached or retained until XML files were updated. The alternative strategy would have not introduced PHP into the set of software required for the presentation.
References
- Beermann & Mihaylov (2014)
- Beermann, D. & Mihaylov, P. (2014). TypeCraft collaborative databasing and resource sharing for linguists. Language Resources and Evaluation, 48(2). 203–225. https://doi.org/10.1007/s10579-013-9257-9
- Dobrin & Ross (2017)
- Dobrin, L. & Ross, D. (2017). The IATH ELAN Text-Sync Tool: A Simple System for Mobilizing ELAN Transcripts On- or Off-Line. Language Documentation & Conservation, 11. 94–102. Retrieved from http://hdl.handle.net/10125/24726
- Thieberger & Jacobson (2010)
- Thieberger, N. & Jacobson, M. (2010). Sharing data in small and endangered languages: Cataloging and metadata, formats, and encodings. In Grenoble, L. & Furbee, N. (Eds.), Language Documentation: Practice and values. (pp. 147–158). John Benjamins Publishing Company. https://doi.org/10.1075/z.158.15thi
- Haig & Schiborr (2016)
- Haig, G. & Schiborr, N. (2016). Multi-CAST (Multilingual Corpus of Annotated Spoken Texts): Ein Projekt zur Erstellung und Auswertung mehrsprachiger Korpora für die Sprachtypologie.
- Michailovsky, Michaud & Guillaume (2011)
- Michailovsky, B., Michaud, A. & Guillaume, S. (2011). A simple architecture for the fine-grained documentation of endangered languages: The LACITO multimedia archive. IEEE. https://doi.org/10.1109/ICSDA.2011.6085973
- Pride, Tomlin & AnderBois (2020)
- Pride, K., Tomlin, N. & AnderBois, S. (2020). LingView: A Web Interface for Viewing FLEx and ELAN Files. Language Documentation & Conservation, 14. 87–107. Retrieved from http://hdl.handle.net/10125/24916
- Schroeter & Thieberger (2006)
- Schroeter, R. & Thieberger, N. (2006). EOPAS, the EthnoER online representation of interlinear text. In Barwick, L. & Thieberger, N. (Eds.), Sustainable Data from Digital Fieldwork. Proceedings of the conference held at the University of Sydney, 4-6 December 2006. (pp. 99–124). Sydney University Press. Retrieved from http://hdl.handle.net/2123/1297
- Thieberger (2006)
- Thieberger, N. (2006). An ethnography of the EthnoER project. Retrieved from http://hdl.handle.net/2123/1532
- Vasile, Guillaume, Aouini & Michaud (2020)
- Vasile, A., Guillaume, S., Aouini, M. & Michaud, A. (2020). Le Digital Object Identifier, une impérieuse nécessité ?L’exemple de l’attribution de DOI à la Collection Pangloss, archive ouverte de langues en danger. I2D - Information, données & documents, 2(2). 155–175. https://doi.org/10.3917/i2d.202.0155
-
Lots of software packages exist for working with corpora, large bodies of text and IGTs. The website, https://corpus-analysis.com is essentially a list of over 100 software solutions of different kinds. ↩︎
-
The tools mentioned in my diagram are the Tsakonian Corpus Platform which depends on Elasticsearch, Sketch Engine and NoSketch Engine, and Blacklab which is developed by CLARIN-NL and can be found on Github. ↩︎
Categories:
Content Mediums:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.