An Analysis of Crubadan OLAC Records
The following are questions I have after looking at the following record:
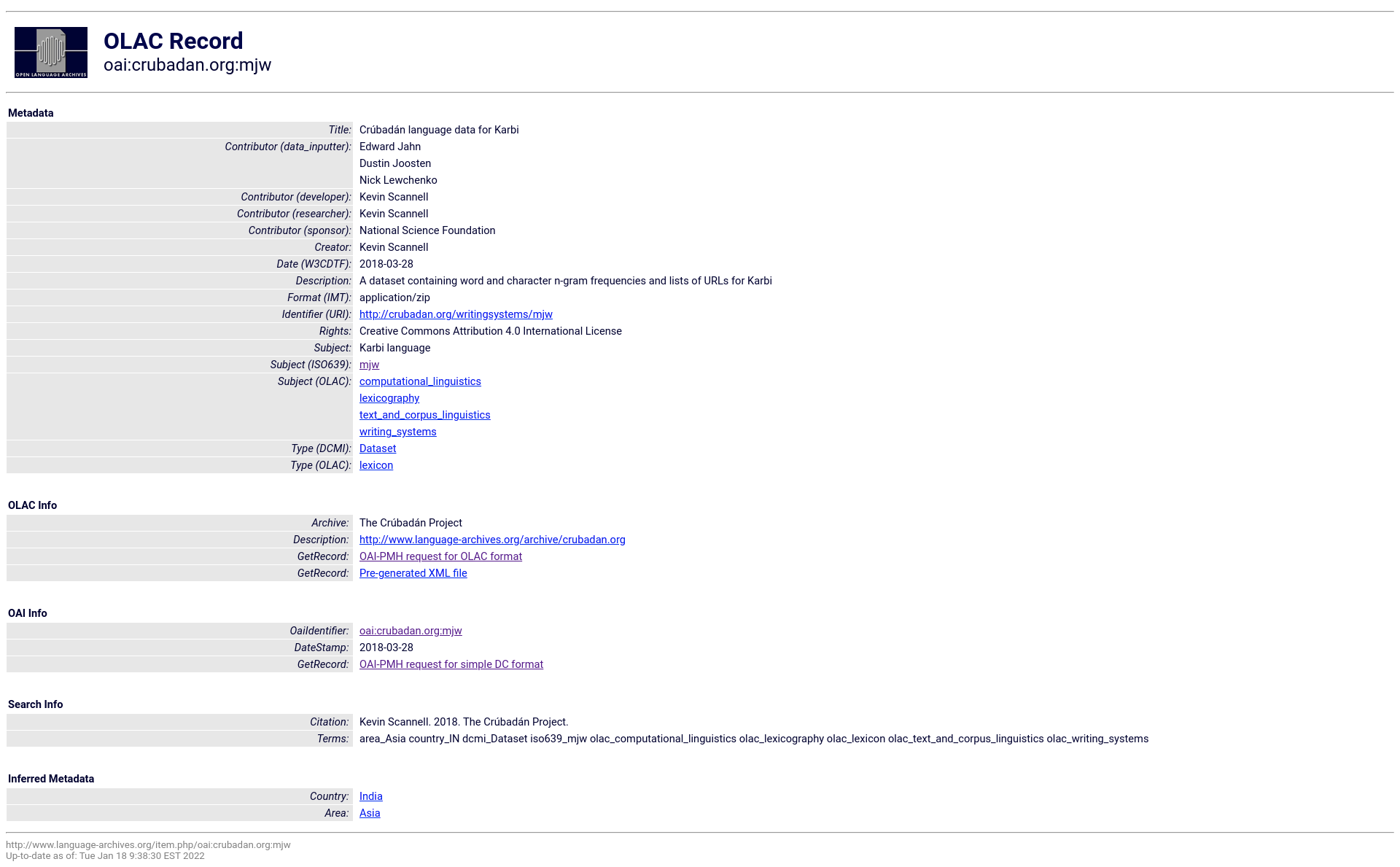
Crubadan record for Karbi (Hills Karbi) in the OLAC Interface Credit: OLAC Interface
- Is the license actually applicable? That is who is the copyright holder and is the content actually meeting the threshold for copyright? The creator is not always the copyright holder. Nor should the creator/author be assumed to be the copyright holder.
- Why is the source text not indicated in the source field?
- Where is the source software used to generate the resource?
- The format is an application/zip and the DCMIType is Dataset, so which application is the data consumable in? or which formats are used within the .zip file?
- If an abstract is a summary, can or should that field be used then to declare what are the rows and columns or tables and relationships in the dataset are?
- How can you have rights without a rights-holder? No copyright holder is declared. The creative commons license is only valid if there is a valid copyright claim.
- The specific resource should have a relationship to a Crubadan collection record. It doesn’t have these relationships declared. This means that the automatically generated OLAC citation is also malformed.
- The part record, all records actually, should have the DCTerms citation element included. These records don’t.
- Why are there no Library of Congress Subject Heading (LCSH) subjects? This is a really hard question to answer. What exactly is the subject of a corpus of letter-frequencies? Computational linguistics? Language Identification? This is where subject hood in language resources seems to break down a bit unless we understand subject to be not just about-ness, but also of-ness and for-ness (utility).
The following two revelations about the user interface ought to be incorporated into future versions of the OLAC interface:
- OLAC presents a citation but doesn’t pull that from the record. Where does it get that information? — What is the generative process?
- Why doesn’t the OLAC interface report that the links are link-rotted and now 404?
- The included XML file appears to be unqualified Dublin Core with the addition of the OLAC metadata. However, the OLAC profile calls for the useage of Qualified Dublin Core. An investigation should be made to see if this is the result of the OLAC infastructure or the data as it was recived by OLAC. (It seems that when this record is compared with the record from PARADISEC OLAC Records and Rights that OLAC does provide QDC when it has been provided QDC.)
The following XML record replicated below is from OLAC. It is retrievable here, while the record is viewable in the OLAC interface here.
<OAI-PMH xmlns="http://www.openarchives.org/OAI/2.0/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/ http://www.openarchives.org/OAI/2.0/OAI-PMH.xsd">
<responseDate>2023-04-04T04:54:39Z</responseDate>
<request verb="GetRecord" identifier="oai%3Acrubadan.org%3Amjw" metadataPrefix="olac">http://www.language-archives.org/cgi-bin/olaca3.pl</request>
<GetRecord>
<record>
<header>
<identifier>oai:crubadan.org:mjw</identifier>
<datestamp>2018-03-28</datestamp>
</header>
<metadata>
<olac:olac xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:olac="http://www.language-archives.org/OLAC/1.1/" xsi:schemaLocation=" http://purl.org/dc/elements/1.1/ http://www.language-archives.org/OLAC/1.1/dc.xsd http://purl.org/dc/terms/ http://www.language-archives.org/OLAC/1.1/dcterms.xsd http://www.language-archives.org/OLAC/1.1/ http://www.language-archives.org/OLAC/1.1/olac.xsd ">
<dc:title>Crúbadán language data for Karbi</dc:title>
<dc:contributor xsi:type="olac:role" olac:code="developer">Kevin Scannell</dc:contributor>
<dc:contributor xsi:type="olac:role" olac:code="researcher">Kevin Scannell</dc:contributor>
<dc:contributor xsi:type="olac:role" olac:code="data_inputter">Edward Jahn</dc:contributor>
<dc:contributor xsi:type="olac:role" olac:code="data_inputter">Dustin Joosten</dc:contributor>
<dc:contributor xsi:type="olac:role" olac:code="data_inputter">Nick Lewchenko</dc:contributor>
<dc:contributor xsi:type="olac:role" olac:code="sponsor">National Science Foundation</dc:contributor>
<dc:creator>Kevin Scannell</dc:creator>
<dc:date xsi:type="dcterms:W3CDTF">2018-03-28</dc:date>
<dc:description>A dataset containing word and character n-gram frequencies and lists of URLs for Karbi</dc:description>
<dc:format xsi:type="dcterms:IMT">application/zip</dc:format>
<dc:identifier xsi:type="dcterms:URI">http://crubadan.org/writingsystems/mjw</dc:identifier>
<dc:rights>Creative Commons Attribution 4.0 International License</dc:rights>
<dc:subject xsi:type="olac:language" olac:code="mjw"/>
<dc:subject xsi:type="olac:linguistic-field" olac:code="computational_linguistics"/>
<dc:subject xsi:type="olac:linguistic-field" olac:code="lexicography"/>
<dc:subject xsi:type="olac:linguistic-field" olac:code="text_and_corpus_linguistics"/>
<dc:subject xsi:type="olac:linguistic-field" olac:code="writing_systems"/>
<dc:type xsi:type="dcterms:DCMIType">Dataset</dc:type>
<dc:type xsi:type="olac:linguistic-type" olac:code="lexicon"/>
</olac:olac>
</metadata>
</record>
</GetRecord>
</OAI-PMH>
Categories:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.