OLAC Customer Segments
There are several paths to website development. Behind every website is an idea, behind successful websites are ideas which have undergone testing and experimentation. The first step in creating a testable hypothesis is to document that proposal and then to set out to test it. Websites can embody business ideas and in some cases business tools like the business model canvas can give a “first stab” look at how different constituents might engage with different components of a website. Eventually, for a well tested website one would want to create user cards and define user pathways through the website as they accomplish user interaction goals on the website. This is generally accepted as good practice in user experience design. Once these pathways are documented and the user actions documented and enabled then testing with real users can commence.
What follows here is my first stab at the types of users which are assumed to use the Open Language Archives Community aggregator website. My breakdown of users here will differ Bird and Simon’s 2022 article: The Open Language Archives Community: A 20-year update published in The Electronic Library.
I present my diagrams using the Business Model Canvas tool, but I am only addressing the basic constituents which can also be found in the simpler Value Proposition Canvas. With regard to these basic constituents some of the points made in Bird and Simons 2022 article fit well with some of the “gains” type statements expected on that canvas. I’m not interested in those statements at this time, but they are important. Rather I want to sus-out how many different classes of constituents there actually are engaging with the website.
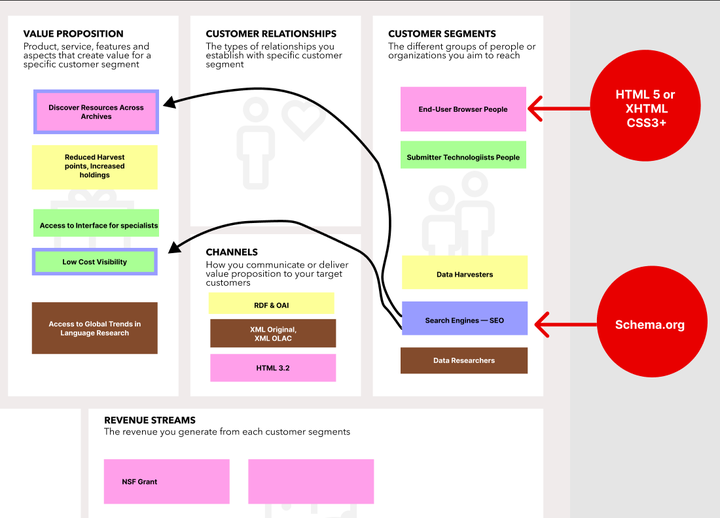
My inital guess is that there are at least five clear constituenties which are interested in interactions on the OLAC website. I outline these as follows:
- End-User Browser People These are real people who come to the site looking to access resources from data providers.
- Submitter Technologists People These are real people who come to the site to work with the tools to check their data feeds and submit data to the website.
- Data Researchers These are real people who come to the site to research the status of resource availability. They are not looking to acquire resources, only to answer questions regarding the nature of the existance of things.
- Data Harvesters These are machines which pull from select data points advertised. One example of this is how Worldcat (OCLC) harvests from OLAC via OAI.
- Search Engines — SEO These are machines which are programmed to crawl the webpages of OLAC’s web interface and index it for some purpose — generally for aggregation in another search interface. An example of this might be Google via the googlebot.
The five classes of constituents Credit: Hugh Paterson III
If we were to draw users pathways for this web experience we would want to identify each of the tasks of each person and then map that to feature and URLs. In this post I am only going to be looking at data types. That is, the kinds of data that each of the constituents desires to interact with or obtain.
- Currently End-user engage with a web-interface which is written in HTML 3.2.
- Submitter technologists also engage with HTML 3.2 based forms.
- Data researchers can engage with and download the XML original, the XML OLAC version, they can also download some RDF style version of the data. These “data dumps” then also support programatic access.
- Unique for programatic access is the OAI interface.
- Search engines currently must use HTTP and encounter HTML 3.2.
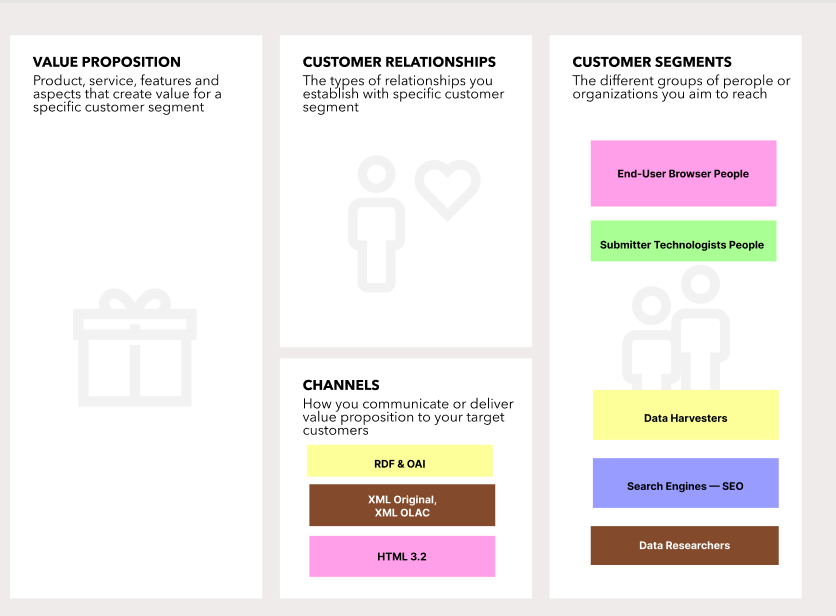
Data Expressions in indicated as channels in the BMC Credit: Hugh Paterson III
In the next image I write down some of the positive reasons that people come to the website. That is, the value they come to the site to recieve. My interpretation is that the following reasons exist for each of the constituenties:
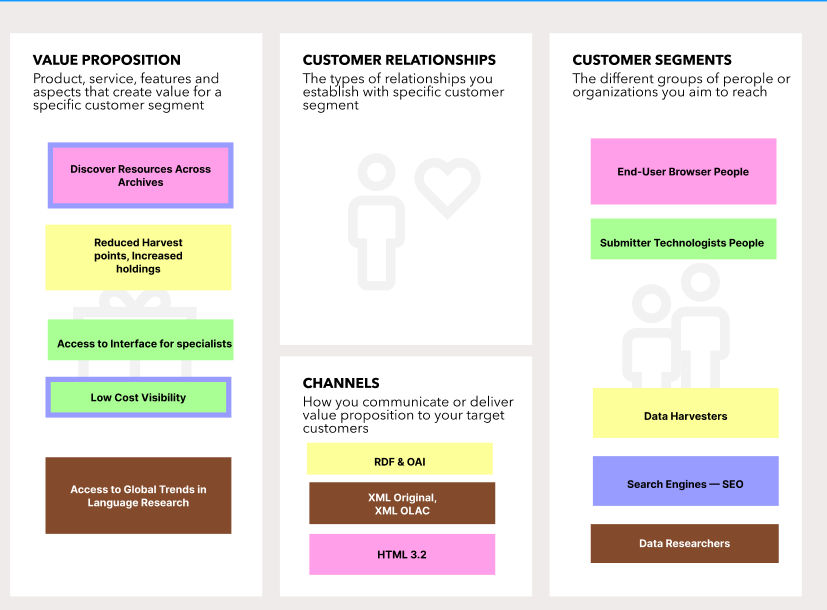
Value Proposition Statements Credit: Hugh Paterson III
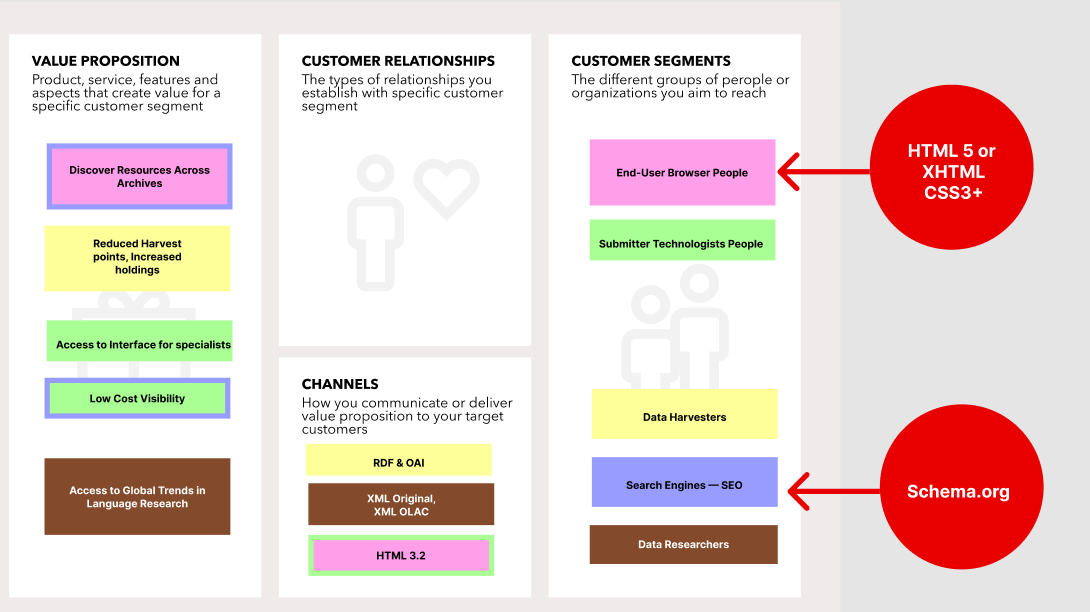
Where technology needs to change to continue to deliver value Credit: Hugh Paterson III
Categories:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.