OLAC: Multi-Audience Service Architecture
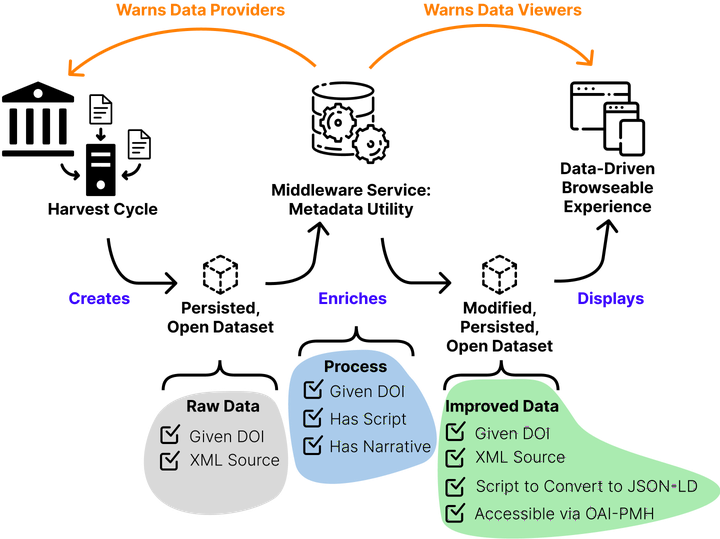
When thinking about rebuilding the OLAC infrastructure the components ought to be built to consider three distinct functions: Harvesting, Data clean-up or Enhancing, and data Engagement (viewing/browsing/exploration).
First there needs to be an OAI-PMH harvester. This harvests the various records from OAI-PMH static and dynamic repositories. This harvest needs to be persisted with an assigned DOI at regular intervals in its XML source format. The harvest represents exactly what data providers are sending to the harvester.
The harvested content then needs to flow through a metadata utility. The utility evaluates the records; assigning a quality metric to each record. The utility then has the power, via scripts, to change values and the structure of the record. These changes ought to be recorded in the OAI provenance section of the record. Changes made need to be communicated back to the data provider as well as to any viewing experience. The exact power of the utility needs to be documented with a text based narrative independent of the code base. The code should be publicly accessible and re-deployable in local environments. The code and its documentation should also be given a DOI; versioned as necessary.
The content which flows out of the utility should be persisted at the same interval that the RAW data is persisted at. It should be persisted in an XML encoding of the OLAC Metadata Application Profile (OAI-PMH ListSet format). Corrected (or enhanced) data should be made available via a dynamic OAI-PMH endpoint. Finally, a script which converts the whole dataset to JSON-LD should available for users who want to convert the data to JSON-LD (as a set).
Finally, the end-user search experience should be a dynamic, responsive website, driven by the metadata in the enhanced dataset. End-user website could use a variety of software magic to enhance human and machine access or awareness to the resources. For example:
- pages about resources can be encoded with schema.org metadata
- search interfaces could leverage other open datasets or ontologies
- metadata from the record could be converted to MODS and made accessible via the unAPI so that tools like Zotero can access the bibliographic information for the resource.
Building the architecture in three distinct parts of the pipeline allows for modular increments to the system. This is desirable for the maintainability of the OLAC infrastructure.
Independent of theses systems are:
- any infrastructure for supporting community activities around maintaining the aggregator and metadata profile
- the new repository onboarding process
- the repository validator — which should be locally exicutable as well as hosted on a server.
Categories:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.