Dublin Core DCMIType Chooser
Some users of Dublin Core choose not to use the DCMIType vocabulary. I find the DCMIType vocabulary deeply integral to good description using the Dublin Core framework. It adds a distinct way to orient the is-ness of the object within the capable description of items via the Dublin Core framework. I admit that it can be confusing at times. For example, I have found some resources which are hard to categorize. I have placed some of these in the following table. The description of the resource is on the left while the ambigious possibilities appear in the right two columns.1
| Object | DCMIType 1 | DCMIType 2 |
|---|---|---|
| Picture made from words | Text | Image |
| Rosetta Stone | Text | PhysicalObject |
| Cassette Tape | Sound | PhysicalObject |
| Moon Rock | PhysicalObject | (I actually think this one is pretty clear) |
| Spatula | PhysicalObject | InteractiveResource |
| Board Game | InteractiveResource | PhysicalObject |
| Uncompiled code | Text | Software |
| Video Game | MovingImage | InteractiveResource |
| ChatBot | Software | InteractiveResource |
| Song on YouTube with just lyrics presented | MovingImage | Collection |
| Catalog of resources | Text | Dataset or Collection |

A picture made of words. Reinhard Döhl, “Apfel” (1965). Note that Arabic art also contains many images constructed of text. Credit: Reinhard Döhl
If we follow the 1-to-1 principle in Dublin Core then only one qualified DCMIType should be applied to any specific record. So which one? I have created the following flowchart to guide a person through the process of selecting the most appropriate DCMIType term. Clicking the diagram opens it up within the mermaid editor where the text can be more easily read.
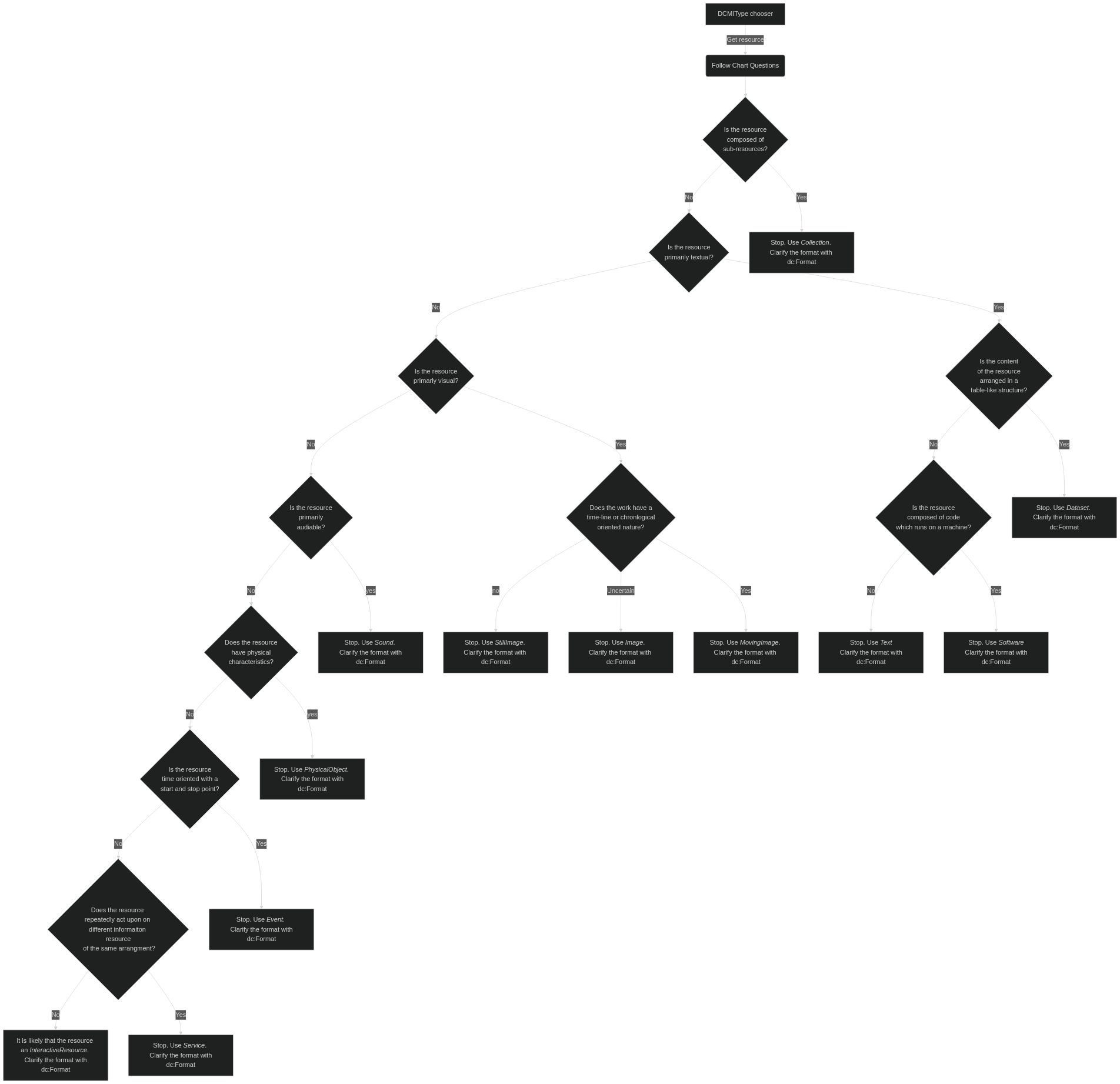
With regards to the distinction between text, dataset, and collection, the OLAC cmmunity brings up an interesting use case.
The Dublin Core™ Collection Description Application Profile suggests that indexes or catalogs of resources ought to be classified as DCMIType Collection. The argument is that these are collection because they are assembled and aggregated.
The term “collection” can be applied to any aggregation of physical and/or digital resources. Those resources may be of any type, so examples might include aggregations of natural objects, created objects, “born-digital” items, digital surrogates of physical items, and the catalogues of such collections (as aggregations of metadata records). The criteria for aggregation may vary: e.g. by location, by type or form of the items, by provenance of the items, by source or ownership, and so on. Collections may contain any number of items and may have varying levels of permanence.
If we take this Application Profile and back-port its semantics to dcterms then a DCMIType collection as defined has some interesting ramifications for resources like lexicons, encyclopedia, corpora, dictionaries, newspapers, edited multi-author works, etc. :
Definition: An aggregation of resources. Comment: A collection is described as a group; its parts may also be separately described.
Resources such as annotated bibilographies, indexes, dictionaries, seem to me to be most accuratly described as DCMIType Text, unless they are being futher described. Even more problematic though is that many of these resources are now engaged with in multiple ways with different audiences. For example, encyclopedias and bibilographies are often read as Text by consumers, but are engaged with as Datasets by producers. Is it possible that DCMIType terms are describing the manifestation? Currently Glottolog sugests that the page that a person accesses a list of resource about the Karbi language is a text resource.

Glottolog 4.6 Resources for Hills Karbi in the OLAC Search Interface Credit: OLAC Search
There is also the remaining question, is the Glottolog page actually an Interactive Resource, which pulls a Dataset?
So, maybe the list of resources is a Collection, the Glottolog itself as a website is an Interactive Resource. The data which drives the website is a Dataset. — leaving nothing as a Text resource?
-
The definition of note of the DCMIType for
Textstates: “Examples include books, letters, dissertations, poems, newspapers, articles, archives of mailing lists. Note that facsimiles or images of texts are still of the genre Text.” So I understand that the apple and the worm image would be classified as text. ↩︎
Categories:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.