Metadata Dynamics for Linguistic and Sociolinguistic Corpora
January 4-5, 2012, I had the opportunity to participate in the LSA’s Satellite Workshop for Sociolinguistic Archival Preparation in Portland, Oregon. There were a great many things I learned there. So here are only a few thoughts. Part of the discussion at the workshop was on how we can make corpora which are collected by Sociolinguists available to the larger Sociolinguistic community. In particular the discussion I am referencing revolved around the standardisation of metadata in the corpora. (In the discussion it was established that are two levels of metadata, “event level” and “corpus level”.) While OLAC gives us some standardization about the corpus level metadata, the event metadata is still unique to each investigation, and arguably this is necessary. However, it was also pointed out that not all “event level” metadata need to be encoded or tracked uniquely. That is, data like date of recording, name of participants, location of recording, gender (male/female) of participant, can all be regularized across the community.
With the above as preface, it is important to realize that we do need to understand that there are still various kinds of metadata which need to be collected. In the workshop it was acknowledged that the field of language documentation was about 10 years ahead of this community of sociolinguists.1 So, I will take an example from the metadata write-up I did for the Meꞌphaa language documentation project. In that project we collected metadata about:
- People
- Equipment
- Equipment settings during recording
- Locations
- Recording Environments
- Times
- Situations
- Linguistic Dynamics
- Sociolinguistic Attitudes
In the following diagram I illustrate the cross cutting of a corpus with these “kinds” of metadata. The heavier, darker line represents the corpus, while the medium heavy lines represent the “kinds” of metadata. Finally, the lighter lines represent the sub-kinds of metadata, where the sub-kinds might be the latitude, longitude, altitude, datum, country, and place name of the location.
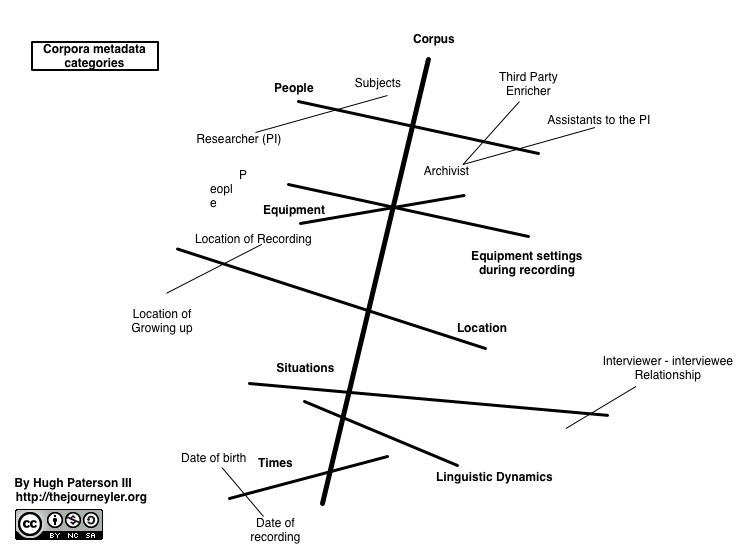
Things to measure Credit: Hugh Paterson III
This does not mean that the corpus does not also need to be cross cut with these other “sub-kinds”. However, these sub-kinds are significantly more in number and will very from project to project. Some of these metadata kinds will be collected in a speaker profile questionnaire. But some of these metadata can only be provided with reflection on the event. To demonstrate the cross cutting of these metadata elements on a corpus I have provided the following diagram. It uses categories which were mentioned in the workshop and is not intended to be comprehensive. In this second diagram, the cross cutting elements might themselves be taxonomies. They may have controlled vocabularies or they may have an open set of possible values, they may also represent a scale.
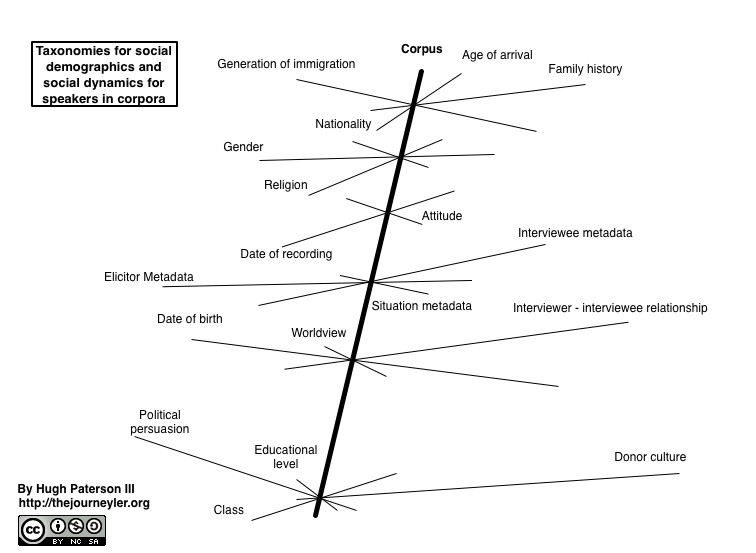
Taxonomies for social demographics and social dynamics for speakers in corpora. Credit: Hugh Paterson III
Both of these diagrams tend to illustrate what in this workshop were referred to a “event level” metadata, rather than “corpus level” metadata.
A note on corpus level metadata v.s. descriptive metadata
There is one more thing which I would like to say about “corpus level” metadata. Metadata is often separated out by function. That is what does the metadata allow us to do, or why is the metadata there? I have been exposed to the following taxonomy of metadata types though course work and in working with photographs and images (Citation: et al., 2009) & (2009). Retrieved from http://www.photometadata.org/node/46 . These classes of metadata are also similar to those posted by JISC Digital Media as they approach issues with Metadata for digital audio (Citation: , 2010) (2010, 1/25). Retrieved from http://www.jiscdigitalmedia.ac.uk/audio/advice/metadata-and-audio-resources/ .
- Descriptive meta-data: supports discovery, attribution and identification of resources created.
- Administrative meta-data: supports management, preservation, and appropriate usage of resources created.
- Technical: About the machinery used to create the resource and the technical aspects of the resource.
- Use and Rights: Copyright, license and moral ownership of the items.
- Structural meta-data: maintains relationships between the parts of complex, multi-part resources (Citation: Spanne, 2008) Spanne, J. (2008). Metadata: Why, What and How (the “Who” is You). .
- Situational: this is metadata which describes the events around the creation of the work. Asking questions about the social setting, or the precursory events. It follows ideas put forward by (Citation: Bergqvist, 2007) Bergqvist, H. (2007). The role of metadata for translation and pragmatics in language documentation. Language Documentation and Description, 4. 163–173. Retrieved from http://www.elpublishing.org/PID/055 .
- Use metadata: metadata collected from or about the users themselves (e.g. user annotations, number of people accessing a particular resource) (Citation: Joint Information Systems Committee (JISC), 2010) Joint Information Systems Committee (JISC)(2010, 3/14). Retrieved from http://www.jiscdigitalmedia.ac.uk/crossmedia/advice/an-introduction-to-metadata/
I think it is only fair to point out to archivist and to librarians that linguists and language documenters do not see a difference between descriptive and non-descriptive metadata in their workflows. That is sometimes we want to search all the corpora by licenses or by a technical attribute. This elevates the these attributes to the function of discovery metadata. It does not remove the function of descriptive metadata from its role in finding things but it does functionally mean that the other metadata is also viable as discovery metadata.
Bibliography
- Bergqvist (2007)
- Bergqvist, H. (2007). The role of metadata for translation and pragmatics in language documentation. Language Documentation and Description, 4. 163–173. Retrieved from http://www.elpublishing.org/PID/055
- (2010)
- (2010, 1/25). Retrieved from http://www.jiscdigitalmedia.ac.uk/audio/advice/metadata-and-audio-resources/
- Joint Information Systems Committee (JISC) (2010)
- Joint Information Systems Committee (JISC)(2010, 3/14). Retrieved from http://www.jiscdigitalmedia.ac.uk/crossmedia/advice/an-introduction-to-metadata/
- Spanne (2008)
- Spanne, J. (2008). Metadata: Why, What and How (the “Who” is You).
- & (2009)
- & (2009). Retrieved from http://www.photometadata.org/node/46
-
What was not well defined in the workshop was what the distinction is between a language documentation corpus and a sociolinguistics corpus. It seems to me as a new practitioner that the chief difference between these two types of corpora is the self identifying quality of researcher. That is does the researcher self-identify as a Sociolinguist or as a Language Documenter. Both types of corpora attempt to get at the vernacular, and both types of corpora collect sociolinguistic facts. It would seem that both corpora are essentially the same (give or take a few metadata attributes). ↩︎
Categories:
Content Mediums:
Organizations:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.