OLAC and Unicode Errors
I am doing some more research on the OLAC data contributors. This time on how they are contributing the contents of serial publications (journal articles). I am doing a search for archives with the search term “serial” in their holdings record.
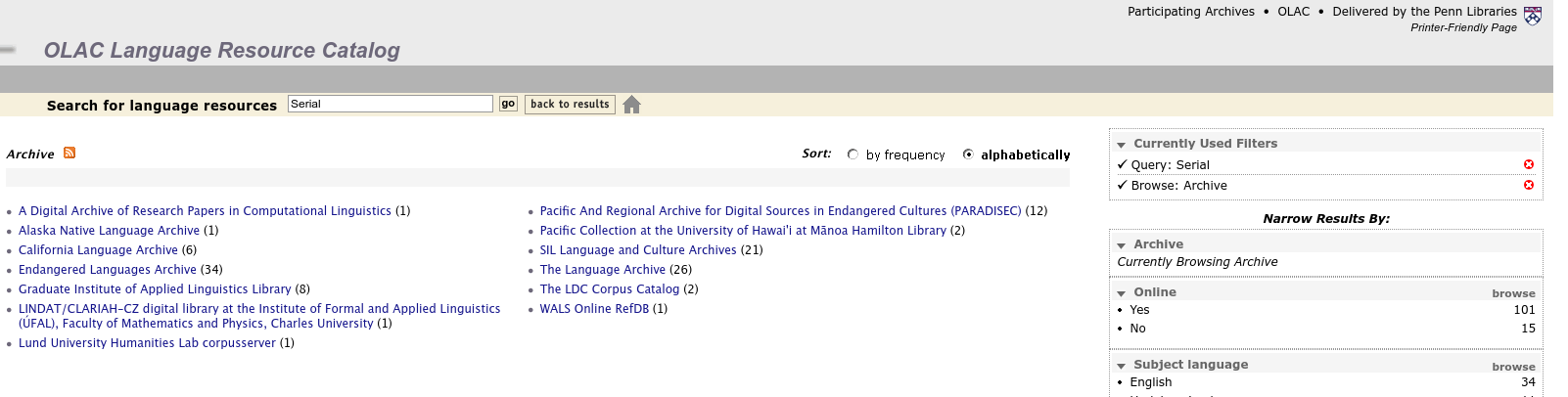
Facceted view of Archives respondin positivly to the term ‘serial’. Credit: OLAC website via Hugh Paterson III
When using the OLAC faceted search and when I click a link for records in the Pacific Collection at the University of Hawai’i at Mānoa Hamilton Library, as seen on the page in link, I get an error message, as seen in the figure below, saying that it is interpreting a character incorrectly (decimal 129, which appears in the file output-library.xsl; Line#: 96; Column#: -1). 1
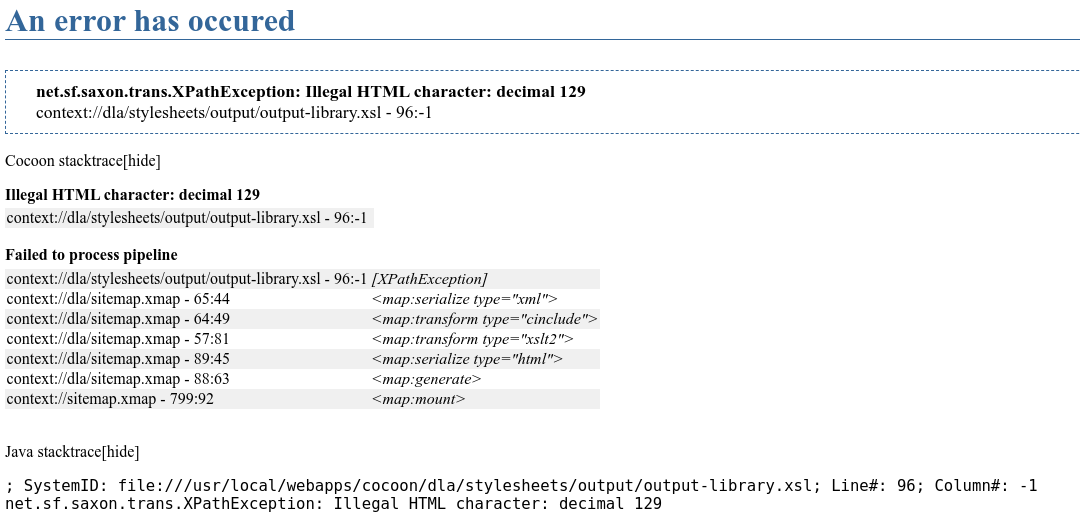
JAVA error Credit: OLAC website via Hugh Paterson III
I am wondering if this is because the input is encoded in Latin Supplement 1(ISO-8859-1 (Latin-1)), rather than Unicode UTF-8, or if it is because of some error on the OLAC processing side. It seems unlikely that a library system would be using decimal 129, which is a control character. I wonder if it left over from a MARC import?
To avoid this problem, it seems that at ingest the OLAC aggregator could use XSLT and map all illegal characters in HTML 4 to a space character. This might solve the problem on the OLAC side for all data feeds as discussed and demonstrated in link [3]. However, I’m still not sure if the data is parsed correctly as in, if the data feed is assumed to be UTF-8 by OLAC but is actually in another encoding format then maybe the parser is assuming that some bits go together to form a character which actually don’t.
After consultation with technicians at the University of Hawai’i, they pointed out that this is likely an error the OLAC server side because this happens whenever there is a diacritic in the record. That is, search results involving diacritics often throw various errors or return no results.
- Archive: The Crúbadán Project
- Archive: LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University
- Subject: !Xóõ
- Subject: Abé
As a test, one can toss in àáâãäåæ into the search bar on this page. http://dla.library.upenn.edu/dla/olac/search.html?q=
Hit search and they get misinterpreted as à áâãäåæ This means that the search interface can not understand UTF-8 encoded text which ought to be the default. If one tries tossing in the upper case of versions ÀÁÂÃÄÅÆ into the search bar, you get an error because they get misinterpreted into the illegal range of HTML characters.
Technical staff at the University of Hawai’i also pointed out that when
testing Unicode characters via a charset converter that the same results appear. For example if one enters the characters àáâãäåæ in the converter and selects convert Latin to UTF-8 and you’ll get the same misinterpreted results as before à áâãäåæ. The situation with upper-case charcters is slightly different. If one tries the upper case letters it just returns back Àà ÂÃÄÅÆ which is clearly wrong since all the letters can’t map to Ã. It is probable that the software is just throwing away the out of bounds characters next to each Ã.
Categories:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.