Abstract
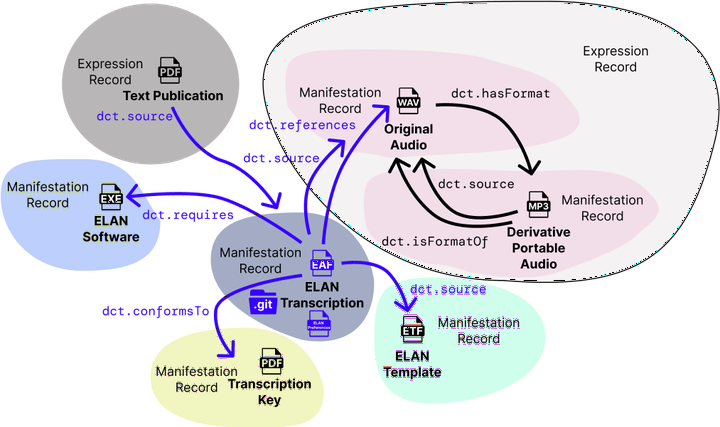
Audio recordings of ethnolinguistic minorities have been created in almost every audio format known. Sometimes these recordings have accompanying transcripts. How should these transcripts be arranged and how should they show up in searches? Older archival resource management practices have divided co-created resources by media type and associated preservation requirements. But language scholars are still making new, born-digital, collections of lesser known languages. Modern digital storage solutions do not require the splitting of digital resources in the same ways. Yet, splitting resources and grouping them, as appropriate in digital systems, facilitates clear description, enhances discovery, and eventual reuse by broad audiences. We present some of the common born-digital workflows used in language scholarship, along with the diverse kinds of resources produced. Resources include: audio, video, still images, participant permission documentation, transcripts, translations, annotations, and collection descriptions. We then discuss how these diverse kinds of resources can be connected in rich, coherent sets of items within digital libraries and institutional repositories using the Open Language Archive Community Application Profile. We show examples from specific collections created in Mexico and Nigeria; presenting resource relationships and descriptions using Dublin Core Metadata. We suggest indexing transcriptions as separate items, but linking them with their audio. This proves to be a useful strategy for both transcribed audio and read texts. This approach is favored over arrangement systems which “bundle” the resources as a single entity.
Categories:
Content Mediums:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.