From Archive to Citation
Abstract
We celebrate the work and trust-building it took to bring PARADISEC to 100TB of language resources. With the rise of the digital language archive and the plethora of referenceable content, a critical question arises: “How easy is it for authors to use existing tools to cite the content they are referencing?” This is especially important as people use archived materials as evidence within published language descriptions.
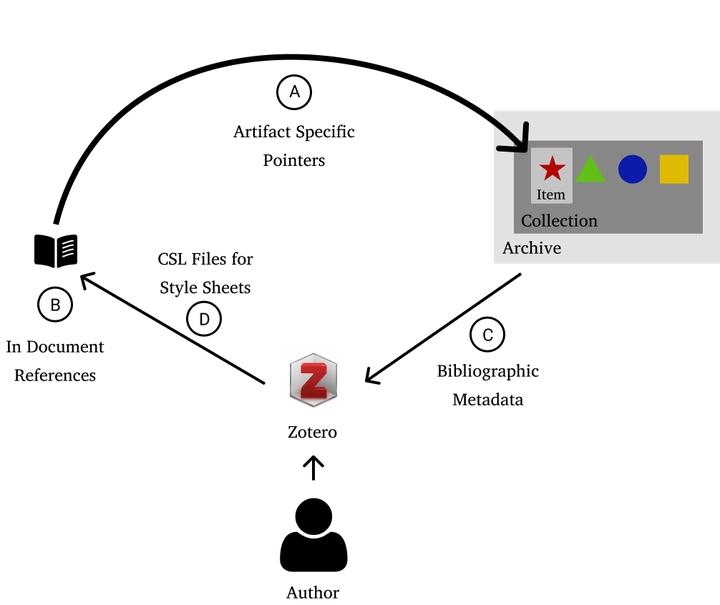
Archived resource metadata is well discussed in language documentation circles; however, citation metadata and its accessibility is less discussed. Discoverability metadata serves aggregators like OLAC filling the function of declaring that something exists. In contrast, citation metadata is about referencing and findability (where is an item located).
In this presentation we look at the interaction between Zotero, an open source citation manager, and the archive. We look at five different archives (PARADISEC, PANGLOSS, SIL Language and Culture Archive, ELAR, and Kaipuleohone) and three methods of importing metadata into Zotero (DOI import, HTML embedded metadata, and file based import). We report on the metadata provided by the archive to the author via Zotero’s interfaces: What’s included, what’s missing, and what’s misaligned.
Understanding the processes by which authors collect metadata for the purpose of citation, what metadata they need, and if it is being provided, facilitates the design of useful interfaces to archives.
Categories:
Content Mediums:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.