From CV to OLAC
Abstract
The Open Language Archive Community (OLAC, Simons & Bird 2003) metadata standards are foundational in sharing the existence of language materials. OLAC was designed to promote resource discoverability across institutional archives. However, anyone can tell OLAC where to look for language materials by publishing a feed (a string of XML data) and pointing OLAC to the feed.
In 2012 at the Satellite Workshop for Sociolinguistic Archive Preparation (LSA, Portland) it was expressed that many people, who might have data, do not have the desire to formally archive their data based on institutional policies. They do not want to openly share the data itself, but they do want people to know it exists. Even if scholars do archive in their institutional repositories, broad-scope search engines (e.g. GoogleScholar) may choose to ignore these resources (Arlitsch & O’Brien 2012). Academically-oriented social networks (academia.edu and researchgate.net) attempt to meet this market demand for discoverability (Ovadia 2014; Niyazov et al. 2016). These solutions fail to aggregate resources based on field-specific formal ontologies. As a result, the work of many retired and late-career linguists is being “lost” to convenient platforms. Convenience also drives some early-career linguists to use costless-deposit archives (Zenodo and OSF) without considering discoverability.
OLAC lists 390,035 items across participating archives (as of July 2020); Glottolog lists 338,158 items as of version 4.2.1. However these numbers do not necessarily reflect the actual language resources archived. Several archives have not recently updated their metadata feed. For instance, the SIL Language and Culture Archive reports that it has 46,000 items (August 2020) but only reports 30,177 to OLAC (last updated in 2013). Even if language materials are deposited in an OLAC participating archive, they may not be discoverable through OLAC. By my calculations, the number of linguistic descriptions grows by approximately 15,000 items per year. Many of these items never find their way into OLAC or Glottolog.
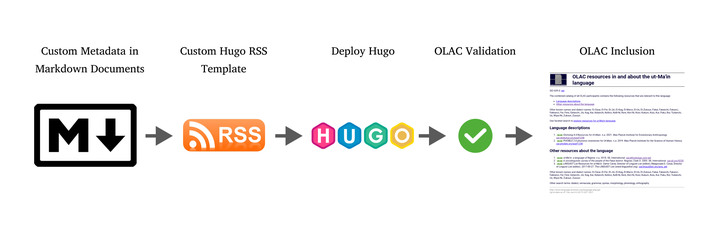
I hold that the best way for researchers to optimize their social profile — advertising their experience and academic output — is to archive their content within institutional repositories but self-host a CV-oriented website, pushing metadata to aggregators. Using open source technologies following strategies outlined by Utomo and Falahah (2020) I use Hugo and the WowChemy theme. With a modified RSS feed that compiles custom metadata and produces an OLAC compliant data feed, the researcher can then advertise language descriptions through OLAC.
Bibliography
- Arlitsch & O'Brien (2012)
- Arlitsch, K. & O'Brien, P. (2012). Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar. Library Hi Tech, 30(1). 60–81. https://doi.org/10.1108/07378831211213210
- Niyazov, Vogel, Price, Lund, Judd, Akil, Mortonson, Schwartzman & Shron (2016)
- Niyazov, Y., Vogel, C., Price, R., Lund, B., Judd, D., Akil, A., Mortonson, M., Schwartzman, J. & Shron, M. (2016). Open Access Meets Discoverability: Citations to Articles Posted to Academia.edu. In Dorta-González, P. (Eds.), PLOS ONE, 11(2). e0148257. https://doi.org/10.1371/journal.pone.0148257
- Ovadia (2014)
- Ovadia, S. (2014). ResearchGate and Academia.edu: Academic Social Networks. Behavioral & Social Sciences Librarian, 33(3). 165–169. https://doi.org/10.1080/01639269.2014.934093
- Simons & Bird (2003)
- Simons, G. & Bird, S. (2003). The Open Language Archives Community: An Infrastructure for Distributed Archiving of Language Resources. Literary and Linguistic Computing, 18(2). 117–128. https://doi.org/10.1093/llc/18.2.117
- Utomo & (2020)
- Utomo, P. & (2020). Building Serverless Website on GitHub Pages. IOP Conference Series: Materials Science and Engineering, 879. 012077. https://doi.org/10.1088/1757-899X/879/1/012077
Categories:
Content Mediums:
Hugh Paterson III
Collaborative Scholar
I specialize in bespoke research at the intersection of Linguistics, Law, Languages, and Technology; specifically utility and life-cycle management for information products in these spaces.